Information access has become a major part when you are designing current day applications. There are fair reasons for this because you may live in a agile world or you have to be part of it. In that case time will be the most critical factor. In the other hand you'll have to consider the performance because it will be one of the most important factors when defining the success of your project or application. The bottom line is you have to invest minimum development time to gain a fair amount of performance when designing you application.
How to use Enterprise data access application block in your application
You can download the enterprise application blocks from codeplex. Then refer it in your application. Use the configuration tool or just add the relevant entries to web.config.

Now you can create an instance from Database class in entlib. This class consists of all 4 major methods you need to do database calls (ExecuteDataSet, ExecuteNonQuery, ExecuteReader, ExecuteScalar). You can execute SQL statements or stored procedures by using each of these methods.
Executing SQL statement

Executing Stored procedures

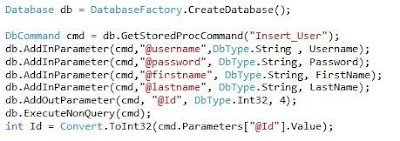
Execute stored procedures with output parameters
Accessor Methods
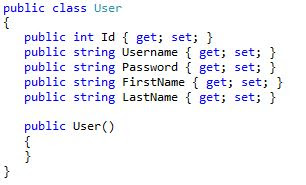
First you need to define an entity with properties which needs to be mapped with your table fields.
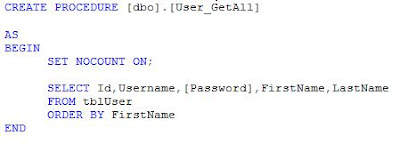
Write a stored procedure to retrieve data
Use the "ExecuteSprocAccessor" method to retrieve a list of users.

or use the ExecuteSqlStringAccessor method

Fortunately I was not forced to agile process by my current environment but when I was designing the Data access layer of my new project, I was thinking about these 2 factors and finally decided to use Microsoft enterprise data access application blocks when designing the data access layer. I don't expect to talk about the advantages of enterprise data access application blocks or compare it with other technologies in this post but main points are it doesn't have performance issues in LINQ to SQL or EF like so much of cost/time it takes to view generation. Anyway according to my experience using an ORM reduces your development time but it gives you other headaches like performance issues and less flexibility when it comes to maintenance in the long run.
Enterprise data access application block is a well-tested data access layer. It manages the database connections pretty well and it doesn’t have any memory leaks so it's performance is quite good and It's easy to integrate to your application. Most of all with entlib 5.0 provides some ORM like features.
How to use Enterprise data access application block in your application
You can download the enterprise application blocks from codeplex. Then refer it in your application. Use the configuration tool or just add the relevant entries to web.config.

Now you can create an instance from Database class in entlib. This class consists of all 4 major methods you need to do database calls (ExecuteDataSet, ExecuteNonQuery, ExecuteReader, ExecuteScalar). You can execute SQL statements or stored procedures by using each of these methods.
Executing SQL statement

Executing Stored procedures

Here you don't need to specify the parameter types or names. You just need to pass the parameters to the stored procedure. Only thing you need to make sure is you need to pass the parameters according to the order they are declared in you stored procedure.
Execute stored procedures with output parameters

Those are the classic methods to execute sql statements or stored procedures but with entlib version 5.0 I have noticed 2 new methods called "ExecuteSprocAccessor" and "ExecuteSqlStringAccessor" where you can return user defined element type record sets which make it more interesting to use entlib DAAB. Here I'll explain how to use these 2 methods.
Accessor Methods
First you need to define an entity with properties which needs to be mapped with your table fields.

Write a stored procedure to retrieve data

Use the "ExecuteSprocAccessor" method to retrieve a list of users.

or use the ExecuteSqlStringAccessor method










